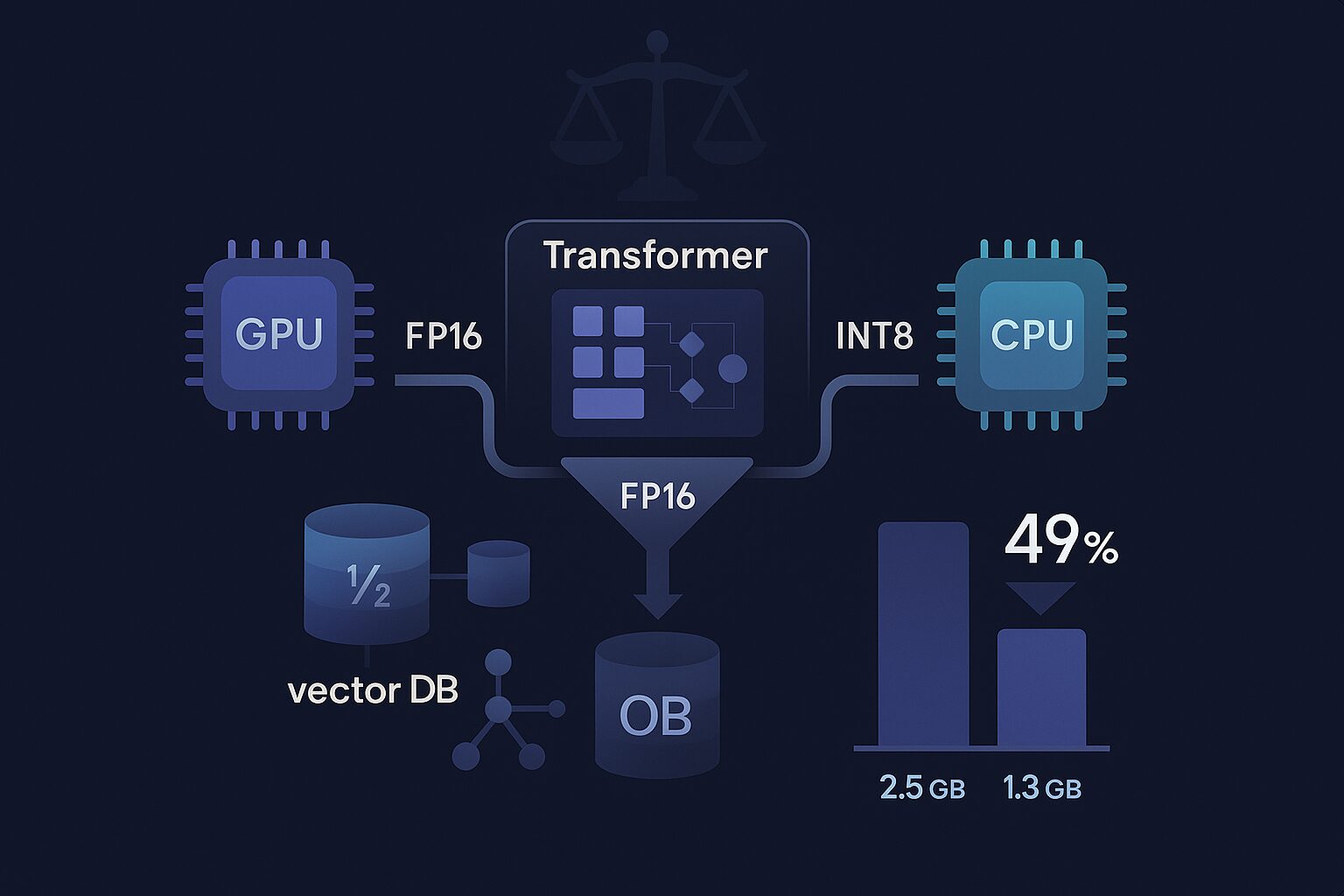
1. 왜 양자화였나?
이번 프로젝트는 화상 기반 AI 법률 상담 플랫폼 LawAId를 개발하는 작업이었다. 사용자 질의에 대해 유사 판례를 검색하고, RAG를 활용해 사건에 대한 AI 분석을 수행하는 전체적인 워크플로우를 다뤘다.
문제는 이런 고정밀 RAG 검색 시스템에 필요한 임베딩 모델과 Cross-Encoder 재정렬 모델을 동시에 로딩해야 했고, 개발 당시 GPU 서버를 사용할 수 없는 환경이었다.
개발 장비는 GTX 3060 Ti (12GB)였으며, Sentence-Transformer와 Cross-Encoder 모델을 동시에 띄우기에는 메모리 한계(OOM)가 명확했다. 실제로 로딩 중 메모리 초과로 서버가 자주 다운되었고, 성능 유지와 리소스 절감을 동시에 해결할 방법이 필요했다.
이를 해결하기 위해 다음 두 가지 최적화를 적용했다:
- GPU에서는 FP16(Half Precision) 양자화를 적용하여 부동소수점 계산을 최적화했다.
- CPU에서는 INT8 동적 양자화를 적용하여 메모리 사용량을 절감했다.
그 결과, 전체 메모리 사용량은 약 49.1% 감소, 동시 처리 수용량도 2배 증가했다.
2. 양자화 개념 정리
양자화란?
양자화는 모델의 가중치(weight)나 활성화(activation) 값을 더 적은 비트 수로 표현하여, 연산량과 메모리 사용량을 줄이는 최적화 기법이다.
예를 들어, 일반적으로 학습된 모델은 32비트 부동소수점(FP32) 형태로 저장되지만, 이를 8비트 정수(INT8)로 변환하면 메모리는 1/4 수준으로 줄어들고, 추론 속도도 최대 4배까지 빨라질 수 있다.
양자화 종류
| 구분 | 설명 | 대표 사례 |
|---|---|---|
| FP32 (기본) | 32비트 부동소수점. 대부분의 모델이 이 형태로 학습됨 | PyTorch 기본 출력 |
| FP16 (Half Precision) | 16비트 부동소수점. 연산 속도는 빠르고, 메모리는 50% 절감 | GPU 환경에서 사용 |
| INT8 (정수 양자화) | 8비트 정수로 표현. 메모리는 75% 절감 | CPU 환경에서 유리 |
FP16의 구조와 변환 원리
INT8과 달리 부동소수점 구조를 유지하는 방식
| 항목 | FP32 | FP16 |
|---|---|---|
| 부호 비트 | 1 | 1 |
| 지수 비트 | 8 | 5 |
| 가수 비트 | 23 | 10 |
FP16은 정수형(INT8)과 달리 실수 표현의 정밀도를 낮추는 방식이다.
정수 기반 양자화보다 정확도 손실이 적지만, GPU 하드웨어 지원이 필수이다.
PyTorch에서는
.half()메서드를 통해 FP16으로 쉽게 전환할 수 있습니다. 단, CPU에서는 동작하지 않으며 에러가 발생한다.
# GPU에서만 사용 가능
model = model.half()양자화 공식
양자화는 실수 값을 정수로 바꾸는 과정이다.
q = round((x - zero_point) / scale) # 양자화(quantize)
x ≈ scale * q + zero_point # 복원(dequantize) x: 원래 실수 값 (예: 0.5)
q: 정수로 변환된 값 (예: 64)
scale: 정수 하나가 몇 개의 실수 단위와 대응되는지
zero_point: 실수 0에 대응되는 정수값 (보통 0 또는 중간값)
INT8 양자화 과정
조건:
실수 범위: [-1.0, 1.0]
정수 범위: [-128, 127] (INT8)
양자화 방식: 대칭(symmetric)
scale = 1.0 / 127 ≈ 0.007874, zero\_point = 0
예) x = 0.5일 때
q = round(0.5 / 0.007874) = round(63.5) = 64 x = 1.0 → q = 127
x = 0.0 → q = 0
x = -1.0→q = -127
>※ 실제 구현에서는 정수 범위를 벗어나는 값을 clamp 처리하여 안정성을 확보한다.
양자화 접근 방식
PyTorch에서 지원하는 주요 양자화 방식은 다음과 같다:
- 사전 학습된 양자화 모델 사용
→ 이미 양자화된 모델을 불러와 그대로 사용하는 가장 간단한 방법
- Post Training Dynamic Quantization (PTQ – 동적)
→ 학습된 모델의 Linear/LSTM 계층을 추론 시점에 INT8로 변환
- Post Training Static Quantization (PTQ – 정적)
→ 사전 Calibration 데이터를 통해 정적 범위를 수집해 양자화
- Quantization Aware Training (QAT)
→ 학습 과정부터 양자화를 시뮬레이션하며 정확도 저하를 최소화
하드웨어별 차별화 이유
CPU ⇒ INT8
- AVX‑512 VNNI 등 정수 연산 가속기로 INT8 dot‑product가 빠르다.
- 8‑bit 가중치로 캐시·메모리 트래픽이 줄어 추론 효율이 높다.
- 서버·로컬 CPU 환경에서 추가 장비 없이 적용하기 쉽다.
GPU ⇒ FP16
- Tensor Cores가 FP16/혼합정밀 연산을 하드웨어로 가속한다.
- PyTorch AMP로 FP16 사용을 안전하게 지원한다.
- FP16은 데이터 폭이 절반이라 같은 대역폭으로 더 많은 텐서를 처리한다.
→ 환경별 권장: CPU=INT8, GPU=FP16.
3. 프로젝트 적용 사례
Linear 층이란?
딥러닝 모델은 여러 층(layer)으로 구성되어 있는데, 그중 Linear 층은 가장 기본적인 형태다.
입력값에 가중치(weight)를 곱하고 편향(bias)을 더해서 출력값을 만들어내는 단순한 행렬 곱셈을 한다.
입력: [1, 2, 3]
가중치: [[0.1, 0.2], [0.3, 0.4], [0.5, 0.6]]
출력: [2.2, 2.8] ← (곱하고 더한 결과)→ 계산이 단순하고 예측 가능하기 때문에 INT8 양자화에도 안정적으로 사용된다.
quantize_dynamic()이란?
PyTorch에서 torch.quantization.quantize_dynamic() 함수는 모델의 지정한 층만 추론 시점에 정수형(INT8)으로 변환해 경량화하는 기능이다.
특히, Linear처럼 계산이 단순한 층은 정확도를 거의 잃지 않고 양자화할 수 있다.
quantized_model = torch.quantization.quantize_dynamic(
model,
{torch.nn.Linear}, # Linear 층만 지정
dtype=torch.qint8
)→ 오직 Linear 층만 INT8로 바뀌며, LayerNorm이나 Attention 같은 복잡한 층은 FP32 유지
→ 동적(Dynamic)이란 추론할 때만 양자화가 일어난다는 뜻 (저장은 FP32)
→ 모델 구조를 크게 바꾸지 않고도 메모리 절감과 속도 향상을 기대할 수 있다.
적용한 모델 및 방식
| 모델 | 역할 | CPU 전략 | GPU 전략 |
|---|---|---|---|
| SentenceTransformer | 텍스트 → 768차원 벡터 변환 | 정적 INT8 양자화 (수동 구현) | FP16 양자화 (.half()) |
| CrossEncoder | 문서 점수 재정렬 | 동적 INT8 양자화 (quantize_dynamic()) |
FP16 양자화 (.half()) |
# FP16 적용 (GPU)
self._model = self._model.half()
# INT8 적용 (CPU)
self._model = torch.quantization.quantize_dynamic(
self._model, {torch.nn.Linear}, dtype=torch.qint8
)양자화 전후 성과 지표
| 평가 항목 | 측정 방법 | 결과 | 의미 |
|---|---|---|---|
| 메모리 효율성 | 로딩 전후 VRAM 차이 측정 | -49.1% | 같은 하드웨어로 2배 많은 모델 실행 가능 |
| 정확도 보존 | 코사인 유사도 계산 | ≥ 0.95 | 원본 모델과 거의 동일한 결과 |
| 시스템 안정성 | OOM 발생 빈도 추적 | 0회/일 | 메모리 부족으로 인한 서비스 중단 완전 해결 |
| 추론 속도 | forward pass 시간 측정 | +20~30% | 같은 작업을 더 빠르게 처리 |
정확도도 함께 확인했으며, 코사인 유사도 기준 0.95 이상을 유지해 성능 손실은 없었다.
4. 배운 점과 주의사항
배운 점
- 하드웨어 특성에 따라 다른 양자화 전략이 필요하다는 걸 배웠다.
- 외부 라이브러리 없이도, PyTorch의 내장 기능만으로도 충분히 안정적인 양자화가 가능했다.
- 메모리 사용량, 처리량, 정확도 같은 정량적인 지표 없이는 최적화의 효과를 객관적으로 판단하기 어렵다는 점도 체감했다.
- 동적 양자화는 pytorch에서 지원하여 안전하고 빠르게 적용할 수 있지만, 정적 양자화는 복잡한 대신 더 큰 메모리 절약 효과를 기대할 수 있다는 차이점을 알게 되었다.
주의사항 및 실측 경험
- FP16은 GPU 전용이다.
.half()를 CPU에서 실행하면 아래와 같은 에러가 발생한다.
RuntimeError: "addmm_impl_cpu_" not implemented for 'Half'→ 따라서 반드시 GPU 환경에서만 FP16을 사용해야 한다.
- INT8 양자화는 Linear 계열에 한정된다.
CNN(Conv2d)처럼 연산이 복잡한 층에 quantize_dynamic()을 적용하면 정확도가 크게 떨어질 수 있다.
→ 이러한 경우는 정적 양자화(static quantization)를 고려해야 한다.
- SentenceTransformer 모델은 수동 처리 필요
구조가 깊고 복잡해서 자동 양자화가 전체 층에 적용되지 않는다.
→ 모든 weight를 순회하면서 직접 양자화해야 했다.
5. 추가로 가볼 길
고도화된 양자화 기법 탐색
| 기법 | 핵심 아이디어 | 장점 | 한계/주의 | 적합한 상황 |
|---|---|---|---|---|
| LLM.int8 | 거대 언어모델의 가중치를 INT8로 변환하되, 민감 채널은 FP16로 유지 | 메모리 절감과 정확도 균형 | 구현·의존성 복잡도, GPU 메모리 패턴 영향 | 대형 LLM 추론, 응답 품질 저하를 최소화해야 할 때 |
| GPTQ | 학습 후(PTQ) weight-only 양자화(주로 4\~8bit) | 속도·메모리 효율 우수, 학습 불필요 | 일부 레이어 왜곡 가능, 모델·데이터 민감 | 온디바이스·단일 GPU 고속 추론 |
| AWQ | 중요 채널을 보존하면서 activation까지 고려해 양자화 | 정확도 방어력 높음 | 준비·튜닝 비용, 구현 난이도 | 정확도 하락을 특히 피해야 하는 서비스 |
마무리
이번 프로젝트를 통해, 제한된 환경에서도 성능을 희생하지 않고 리소스를 절감하는 방법을 직접 설계하고 검증할 수 있었다. 특히 GPU 서버 없이 고도화된 검색 모델을 구축하면서, 하드웨어별 최적화 전략의 중요성을 절실히 느꼈다.
양자화는 단순한 경량화가 아닌, AI 서비스를 실현 가능하게 만드는 기술적 기반임을 확인한 경험이었다.