1. CPU 스케줄링
CPU 스케줄링과 CPU 스케줄러
- CPU 스케줄링(CPU Scheduling)
여러 프로세스(또는 스레드)가 CPU 자원을 효율적으로 공유하도록 하는 운영체제의 기법
이 스케줄링 로직(알고리즘)을 결정·수행하는 운영체제 일부를 CPU 스케줄러(CPU Scheduler) 라고 함
- 프로세스 vs 스레드
CPU 스케줄링의 대상은 실행 문맥(Context) 을 가진 모든 것(프로세스뿐 아니라 스레드도 포함)
보통 “프로세스를 스케줄링한다”라고 표현하더라도, 사실상 ‘실행 문맥’을 가진 대상을 스케줄링한다고 볼 수 있음
우선순위 (Priority)
- 모든 프로세스가 CPU를 필요로 하므로, 운영체제는 공정하고 합리적인 방법으로 자원을 할당해야 함
- 우선순위(Priority) 를 PCB에 기록하고, 우선순위가 높은 프로세스에 더 빨리·많이 CPU 할당
- (리눅스 기준) 특정 프로세스의 우선순위를 조정하고 싶다면,
nice값을 변경해서 상대적 우선순위를 높이거나 낮출 수 있음 - 가장 대표적인 고려 요소 중 하나는 CPU 활용률(CPU Utilization)
- I/O가 많은 프로세스(I/O bound): CPU를 짧게 자주 사용 → 우선순위를 높게 부여하면 CPU와 I/O가 계속 효율적으로 돌아감
- CPU 집중(CPU bound) 프로세스: CPU를 오래 사용 → 상대적으로 우선순위가 낮을 수 있음
스케줄링 큐
- 운영체제는 프로세스가 자원을 사용하기 전에 큐(Queue) 를 통해 차례로 기다리도록 함
- 대표적으로 준비 큐(Ready Queue) 와 대기 큐(Waiting Queue) 가 있음
- 준비 큐: CPU를 이용하고자 기다리는 프로세스 PCB
- 대기 큐: I/O 등으로 대기 상태가 된 프로세스 PCB
- 프로세스는 준비 상태에서 디스패치(Dispatch) 로 CPU를 받아 실행 상태가 되며, 시간이 만료되면(타이머 인터럽트) 다시 준비 큐로 돌아가고, 실행 중 I/O를 요청하면 대기 큐로 이동했다가 I/O 완료 시 준비 큐로 돌아옴
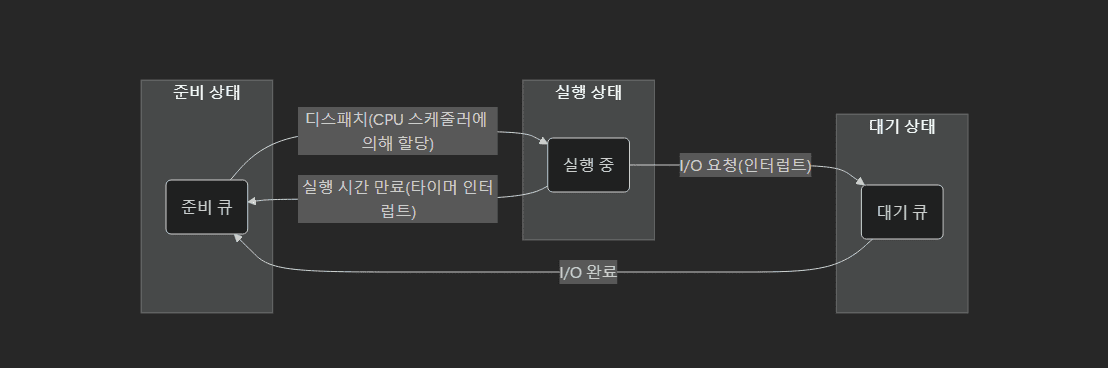
참고
– “준비 큐 → 실행 상태”는 CPU 스케줄러가 CPU를 어느 프로세스에 할당할지 결정하여 디스패치(Dispatch)하는 과정이다.
– “실행 상태 → 준비 큐”는 타이머 인터럽트나 우선순위 등에 의해 선점(Preemption)이 일어나는 경우에 발생한다.
선점형과 비선점형 스케줄링
- 선점형(Preemptive) 스케줄링
- 현재 실행 중인 프로세스가 있어도, 운영체제가 강제로 CPU를 빼앗아 다른 프로세스에게 할당 가능
- 문맥 교환(컨텍스트 스위칭) 오버헤드는 증가하나, 한 프로세스의 독점을 막고 여러 프로세스에 CPU를 골고루 분배 가능
- 비선점형(Non-preemptive) 스케줄링
- 실행 중인 프로세스가 종료되거나 스스로 대기 상태로 들어가야만 다른 프로세스에 CPU를 넘길 수 있음
- 상대적으로 문맥 교환 오버헤드가 적지만, 긴 작업이 CPU를 오래 점유하면 다른 프로세스들이 대기하게 됨
2. 대표적인 CPU 스케줄링 알고리즘
선입 선처리 스케줄링 (FCFS: First Come First Served)
- FCFS: 준비 큐에 삽입된 순서대로 CPU를 할당
- 직관적이고 단순하지만, 먼저 들어온 긴 작업 때문에 뒤에 짧은 작업이 오래 대기할 수 있음 → 호위 효과(Convoy Effect) 발생 가능
최단 작업 우선 스케줄링 (SJF: Shortest Job First)
- SJF: 준비 큐에서 CPU 사용 시간이 가장 짧은 프로세스부터 우선 실행
- 비선점형이 기본이지만, 선점형으로 확장하면 SRT(Shortest Remaining Time) 가 됨
- 평균 대기 시간을 최소화한다는 장점이 있지만, 실제 CPU 사용 시간을 정확히 예측하기 어렵다는 단점이 있음
라운드 로빈 스케줄링 (RR: Round Robin)
- RR: FCFS에 타임 슬라이스(Time Slice) 개념을 추가한 선점형 알고리즘
- 준비 큐에 있는 프로세스에게 일정 시간만 CPU를 할당 → 시간이 끝나면 문맥 교환 후 큐의 뒤로 이동
- 모든 프로세스가 비교적 공정하게 CPU를 나누어 쓰며, 대화형 시스템에서 유리
- 타임 슬라이스가 너무 작으면 문맥 교환이 잦아져 오버헤드가 증가할 수 있으므로, 적절한 타임 슬라이스 설정이 매우 중요
최소 잔여 시간 우선 스케줄링 (SRT: Shortest Remaining Time)
- SRT: SJF + 라운드 로빈의 선점형 특성을 합친 방식
- 라운드 로빈처럼 일정 시간 단위로 선점 가능하며, 그 시점에 남은 CPU 사용 시간이 가장 짧은 프로세스에게 CPU 할당
우선순위 스케줄링 (Priority Scheduling)
- 프로세스마다 우선순위(Priority) 를 부여하고, 우선순위가 가장 높은 프로세스부터 실행
- 우선순위가 낮은 프로세스가 무한정 대기하는 아사(Starvation) 문제 발생 가능
→ 오랜 대기 프로세스의 우선순위를 점차 높이는 에이징(Aging) 기법으로 해결
다단계 큐 스케줄링 (Multilevel Queue)
- 여러 개의 준비 큐를 사용, 우선순위가 가장 높은 큐부터 우선 처리
- 각 큐는 별도의 스케줄링 방식(예: RR, FCFS 등)을 가질 수 있음
- 큐 간 이동 불가 → 우선순위가 영구히 낮은 큐에 속하면 아사 문제가 발생할 수도 있음
다단계 피드백 큐 (Multilevel Feedback Queue)
- 다단계 큐에서 프로세스가 큐 사이를 이동 가능하도록 확장한 방식
- 우선순위가 높은 큐에 처음 진입, 주어진 타임 슬라이스 동안 처리 후 완료되지 않으면 낮은 큐로 이동
- 오래 CPU를 쓰는(CPU bound) 프로세스는 우선순위가 점차 낮아지고, I/O bound 프로세스는 높은 우선순위 큐에서 빠르게 처리
- 낮은 큐에 오래 머무른 프로세스의 우선순위를 높이는(에이징) 기법으로 아사 문제를 방지
3. 리눅스 CPU 스케줄링
| 스케줄링 정책 | 적용 상황 |
|---|---|
| SCHED_FIFO | 실시간 프로세스 (매우 높은 우선순위) |
| SCHED_RR | 실시간 프로세스 (매우 높은 우선순위, 라운드 로빈 방식) |
| SCHED_NORMAL | 일반 프로세스 (기본 정책) |
| SCHED_BATCH | 일반 프로세스 중 배치 작업에 적용 (우선순위 고려 안 함) |
| SCHED_IDLE | 우선순위가 매우 낮은 프로세스에 적용 |
- 일반 프로세스에는 기본적으로 SCHED_NORMAL 정책이 적용되며, 내부적으로 CFS(Completely Fair Scheduler) 사용
- CFS:
- 각 프로세스마다 가상 실행 시간(
vruntime)을 두어, 이 값이 가장 작은 프로세스부터 스케줄링 vruntime은 실제 실행 시간 + 우선순위(가중치)를 고려 (우선순위가 높으면 가중치가 커서 더 많은 CPU 시간 할당)
4. 가상 메모리
물리 주소와 논리 주소
- 물리 주소(Physical Address): 실제 RAM 상의 주소
- 논리 주소(Logical Address): 프로세스마다 독립적으로 0번지부터 시작하는 주소 체계
- MMU(Memory Management Unit): CPU가 사용하는 논리 주소를 물리 주소로 변환해 주는 하드웨어 장치
연속 메모리 할당과 스와핑(Swapping)
- 연속 메모리 할당: 프로세스가 메모리 공간을 연속적으로 할당받는 방식
- 프로세스 실행/종료가 반복되면서 사이사이에 빈 공간(외부 단편화)이 생김 → 메모리 낭비 문제
- 스와핑: 메모리에 올라온 프로세스 중 현재 실행되지 않는 프로세스를 스왑 영역(보조기억장치)에 내보내고(스왑 아웃), 필요할 때 다시 불러오는(스왑 인) 방식
- 현대 운영체제에서는 스와핑을 최소화하고, 주로 페이지 단위 교체(page replacement) 로 메모리를 효율적으로 관리
페이징(Paging)으로 가상 메모리 관리
- 프로그램 전체를 모두 메모리에 두지 않고, 일부만 적재해도 실행 가능 → 가상 메모리(Virtual Memory)
- 페이징(Paging)
- 논리 주소 공간을 일정한 크기의 페이지(Page) 로 나누고, 물리 메모리를 동일한 크기의 프레임(Frame) 으로 분할
- 페이지를 불연속적으로 할당 가능 → 외부 단편화 문제 해결
- 하지만 페이지 크기에 딱 맞추지 못하면 내부 단편화가 발생할 수 있음
- 페이징 시스템에서도 필요에 따라 페이지 단위로 스왑 아웃/인 가능 → 전체 프로세스를 통째로 이동할 필요가 없음
외부 단편화와 내부 단편화
외부 단편화 (External Fragmentation)
- 연속 메모리 할당 시, 프로세스 실행·종료가 반복되면 메모리 사이사이에 작은 빈 공간(Free Space)이 생길 수 있음
- 빈 공간의 총합은 충분해도 연속된 공간이 부족해 새 프로세스를 할당하기 어려워지는 문제
- 이 문제를 해결하기 위해 메모리 압축(Compaction)을 수행할 수 있지만, 오버헤드가 큼
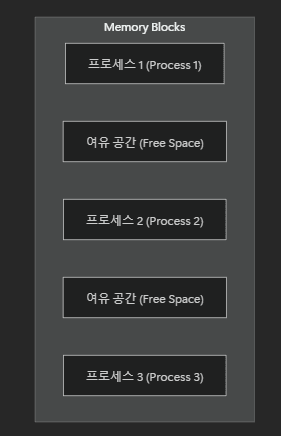
내부 단편화 (Internal Fragmentation)
- 페이징(Paging)처럼 고정 크기 단위로 메모리를 할당할 경우, 실제 필요한 양보다 큰 페이지를 할당받아 남는 공간이 발생할 수 있음
- 페이지 크기가 커질수록 낭비되는 내부 단편화도 커지지만, 크기를 너무 줄이면 페이지 테이블이 커져 관리 오버헤드가 증가

페이지 테이블(Page Table)
- 각 페이지가 어느 프레임에 매핑되는지 정보를 저장한 테이블
- 유효 비트(Valid Bit): 해당 페이지가 메모리에 있는지(1), 보조기억장치에 있는지(0)
- 0인 페이지 접근 시 페이지 폴트(Page Fault) 발생 → 해당 페이지를 메모리에 가져옴
- 보호 비트(Protection Bit): 페이지 접근 권한(읽기/쓰기/실행 등)
- 참조 비트(Reference Bit): CPU가 해당 페이지에 접근한 적이 있는지(0 또는 1)
- 수정 비트(Modified/Dirty Bit): 해당 페이지에 쓰기 작업이 일어났는지 여부
페이지 테이블과 메모리 접근
- 프로세스 실행 시, PTBR(Page Table Base Register) 를 통해 페이지 테이블 시작 위치를 참조
- 페이지 테이블 전체를 메모리에 둘 경우, 매번 주소 변환 시 메모리를 2번 접근해야 함
→ TLB(Translation Look-aside Buffer) 라는 캐시 사용
계층적 페이징(Multilevel Paging)
- 페이지 테이블이 매우 커질 경우, 이를 여러 단계로 분할해 관리 (예: 2단, 3단 페이지 테이블 등)
- CPU 가까이에 Outer 페이지 테이블 등을 두고, 하위 테이블은 필요할 때만 로드
→ 모든 페이지 테이블을 항시 메모리에 둘 필요가 없어 메모리 사용 절약
페이징 주소 체계
- 논리 주소는
<페이지 번호, 변위(offset)>로 구성
1. 페이지 번호로 어떤 프레임에 매핑되는지 찾고
2. 변위로 프레임 내 실제 위치를 결정
5. 페이지 교체 알고리즘
요구 페이징(Demand Paging)
- CPU가 페이지 P에 접근 시도
- P가 메모리에 있으면(유효 비트=1) 그대로 접근
- 없으면(유효 비트=0) 페이지 폴트 발생 → 디스크에서 P를 메모리로 읽어옴(페이지 인) → 유효 비트=1
- 다시 접근 시도
- 순수 요구 페이징: 초기에는 아무 페이지도 메모리에 로드하지 않고, 페이지 폴트가 날 때마다 로드
- 메모리가 가득 찬 상태에서 새 페이지를 가져와야 한다면, 기존 페이지 중 하나를 스왑 아웃(페이지 교체)
페이지 교체 알고리즘
- FIFO
- 먼저 들어온 페이지부터 교체
- 구현이 단순하지만, 자주 사용 중인 페이지가 쉽게 제거될 수도 있어 효율이 떨어질 수 있음
- Optimal(OPT)
- 앞으로 가장 나중에 사용할 페이지(또는 사용 빈도가 가장 적은 페이지)를 교체
- 이론적으로 페이지 폴트를 최소화하지만, 실제 미래 접근을 알 수 없으므로 구현이 불가능에 가까움
- LRU(Least Recently Used)
- 가장 오랫동안 사용되지 않은 페이지를 교체
- 과거 기록을 통해 미래 사용 가능성을 추정하는 방식
- 실제 시스템에서 가장 흔히 쓰이는 기법 중 하나
- 구현 방식에는 카운터 기반, 스택 기반 등 다양한 방법이 있음
- 스래싱(Thrashing)
- 페이지 폴트가 지나치게 자주 발생해, 실제 작업보다 페이지 교체(디스크 I/O)에 더 많은 시간이 소모되는 상태
- 심하면 전체 시스템 성능이 급격히 저하됨
6. 파일 시스템
파일과 디렉터리
- 파일(File)
- 이름, 실행 정보, 부가 정보(메타데이터) 등으로 구성
- 프로세스는 운영체제가 제공하는 파일 디스크립터(File Descriptor) 로 파일을 식별
- 디렉터리(Directory)
- 여러 파일을 트리 구조로 관리
- 각 항목(파일/디렉터리)을 디렉터리 엔트리(Directory Entry) 로 기록
- 경로(path)를 통해 트리 상의 위치를 지정
- 디렉터리 자체도 운영체제 관점에서 ‘파일’로 취급
파일 할당
- 운영체제는 보조기억장치에 파일을 블록(Block) 단위로 저장
- 연결 할당(Linked Allocation)
- 각 블록에 다음 블록의 주소를 포인터로 기록
- 색인 할당(Indexed Allocation)
- 모든 블록 주소를 색인 블록(Index Block) 에 모아서 관리
- 파일이 매우 큰 경우 여러 색인 블록을 연결하거나 다중 레벨 색인 기법을 적용할 수도 있음
파티셔닝(Partitioning)과 포매팅(Formatting)
- 한 보조기억장치를 여러 파티션(Partition) 으로 나눠, 각 파티션마다 다른 파일 시스템을 적용 가능
- 포매팅(Formatting): 어떤 파일 시스템을 적용할지 결정하고, 새 데이터를 쓸 준비를 하는 과정
아이노드(Inode) 기반 파일 시스템
- 리눅스 EXT 계열 등 많은 파일 시스템에서, 아이노드(Inode) 라는 색인 블록을 사용
- 아이노드는 파일의 메타데이터 + 실제 데이터 블록 위치 정보를 포함
- 하드 링크(Hard Link)
- 원본 파일과 같은 아이노드를 공유
- 실제 데이터가 동일하므로, 원본 파일이 삭제되어도 링크가 남아 있으면 데이터 접근 가능
- 심볼릭 링크(Symbolic Link)
- 별도의 아이노드에 원본 파일의 경로만 기록
- 원본 파일이 삭제·이동되면 링크가 깨짐
7. 마운트와 부팅
마운트(Mount)
- 다른 저장장치(파티션)의 파일 시스템을 현재 디렉터리 구조에 연결하여 접근 가능하게 하는 과정
부팅(Booting)
- 컴퓨터 전원을 켜면, BIOS 가 하드웨어를 검사(POST)하고, MBR(Master Boot Record) 에서 부트로더(bootstrap)를 실행
- 부트로더가 커널(운영체제 핵심)을 메모리에 적재 → 시스템 구동 시작
8. 가상 머신과 컨테이너
가상 머신(Virtual Machine)
- 하드웨어 수준 가상화를 통해, 하나의 물리적 하드웨어 위에 여러 게스트 OS(가상 컴퓨터)를 구동
- 하이퍼바이저(Hypervisor): 가상 머신을 만들고 관리하는 소프트웨어
- 각 VM은 독립적인 OS 및 애플리케이션을 운영
- 높은 격리성을 갖지만, 별도의 게스트 OS(커널 등)를 유지해야 하므로 오버헤드가 비교적 큼
- VM마다 커널을 포함해 리소스가 할당되므로, 호스트 자원이 크게 소모될 수 있음
컨테이너(Container)
- 운영체제 수준 가상화 방식으로, 호스트 OS의 커널을 공유하면서 프로세스와 라이브러리 등을 격리
- 대표적으로 Docker, LXC 등이 있으며, VM보다 가볍고 빠르게 애플리케이션을 배포·운영 가능
- 컨테이너 오케스트레이션 (예: Kubernetes): 대규모 컨테이너 배포, 스케일링, 로드밸런싱 등을 자동화하여 체계적으로 관리
- VM에 비해 리소스 사용량이 훨씬 적고, 애플리케이션 구동 속도도 빠르지만, 커널을 공유하기에 VM만큼의 격리성이 필요할 때는 적합하지 않을 수 있음
참고
_이것이 취업을 위한 컴퓨터 과학이다 with CS 기술 면접 – 한빛미디어_