1. 메모리 기초
1.1 메모리와 RAM
- 메모리는 실행 중인 프로그램이 올라가는 공간이다.
- 메인 메모리는 주로 RAM을 의미한다. RAM은 전원이 끊기면 데이터가 사라지는 휘발성 저장장치이다.
- CPU는 보조 기억 장치(예: HDD, SSD)에서 프로그램을 직접 가져와 실행할 수 없으므로, 반드시 RAM으로 프로그램과 데이터를 복사해야 한다.
- RAM 용량이 크면 동시에 여러 프로그램을 실행하기 유리하다.
RAM의 종류
- DRAM
- SRAM
- SDRAM
- DDR SDRAM
1.2 빅 엔디안 vs. 리틀 엔디안
- 멀티바이트 데이터를 어떤 순서로 메모리에 저장하느냐에 따라 구분한다.
- 빅 엔디안: 낮은 번지 주소에 상위 바이트를 먼저 저장. 사람이 읽는 숫자 체계와 비슷해 디버깅이 편리하다.
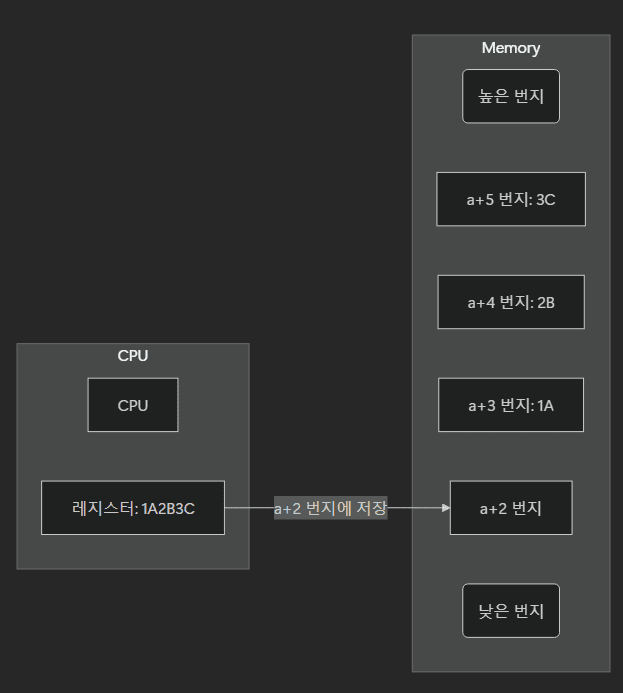
- 리틀 엔디안: 낮은 번지 주소에 하위 바이트를 먼저 저장. 덧셈 등 수치 계산에 유리하다.
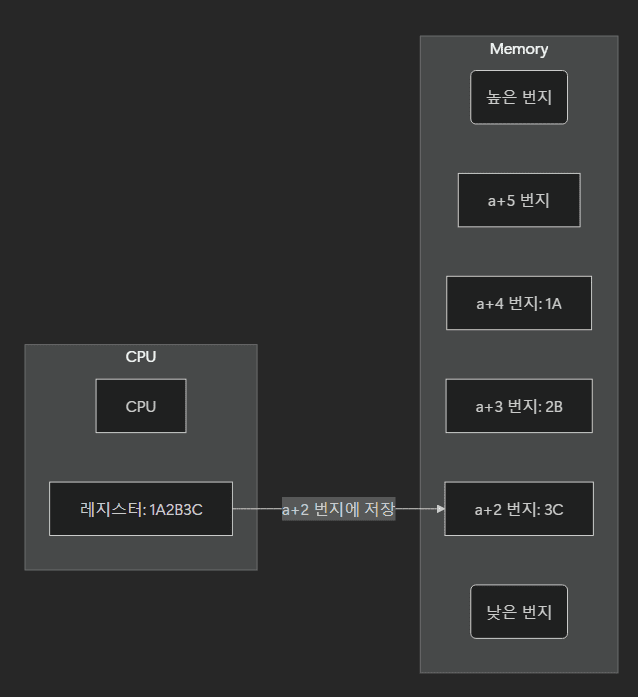
- 바이 엔디안: 빅 엔디안과 리틀 엔디안 중 하나를 선택할 수 있는 구조이다.
2. 캐시 메모리
2.1 캐시의 등장 배경
- CPU는 매우 빠르게 연산하지만, 메모리는 상대적으로 느리다. 이 차이를 줄이기 위해 CPU와 메모리 사이에 고속의 캐시 메모리를 두었다.
- 캐시는 보통 SRAM 기반으로, 필요한 데이터를 미리 가져와 CPU에 빠르게 전달한다.
2.2 캐시 구조와 종류
- L1 캐시 → L2 캐시 → L3 캐시 순으로 CPU 코어와 가까워질수록 작고 빠른 특성을 갖는다.
- L1 캐시는 명령어 전용(I-캐시)과 데이터 전용(D-캐시)으로 나뉘기도 한다(분리형 캐시).
2.3 캐시 히트와 캐시 미스
- 캐시 히트: CPU가 실제로 필요한 데이터가 캐시에 있는 경우.
- 캐시 미스: 캐시에 데이터가 없어 CPU가 메모리까지 직접 접근해야 하는 경우.
- 캐시가 효율적으로 작동하려면 참조 지역성 원리가 중요하다.
- 시간 지역성: 한 번 참조한 데이터를 다시 참조할 가능성이 높다. (ex. 자주 사용하는 변수)
- 공간 지역성: 인접한 주소의 데이터를 참조할 가능성이 높다. (ex. 배열 요소)
2.4 캐시 쓰기 정책과 일관성
- 즉시 쓰기(Write-through): 캐시와 메모리에 동시에 데이터를 갱신한다.
- 메모리가 항상 최신 상태를 유지하지만, 쓰기 동작이 잦아 버스 사용량이 늘어난다.
- 지연 쓰기(Write-back): 우선 캐시에만 쓰고, 일정 시점에 몰아서 메모리에 반영한다.
- 성능은 좋으나 데이터 불일치 문제가 발생할 수 있어, 캐시 일관성을 위한 메커니즘이 필요하다.
Note: 캐싱을 한다는 것은 데이터 접근 속도를 높이지만, 동시에 데이터 일관성을 유지하기 위한 책임이 뒤따른다.
3. 보조 기억 장치와 I/O
3.1 보조 기억 장치
- 보조 기억 장치(HDD, SSD 등)는 전원이 꺼져도 데이터를 보관하는 역할을 한다.
- HDD는 자기 디스크와 헤드를 이용해 데이터를 읽고 쓰고, SSD는 플래시 메모리를 활용해 전기적 방식으로 동작한다.
RAID
- RAID(Redundant Array of Independent Disks)는 다수의 디스크를 하나처럼 묶어 안전성 또는 성능을 높이는 기술이다.
- RAID0: 데이터를 여러 디스크에 분산(스트라이핑)해 빠른 속도를 얻지만, 안정성이 낮다.
- RAID1: 데이터를 복제(미러링)하여 안정성이 높지만, 저장 효율이 떨어진다.
- RAID4/5/6: 패리티 정보를 활용하여 안정성을 높인다.
- RAID4: 패리티를 전용 디스크에 저장하므로 패리티 디스크에서 병목이 발생한다.
- RAID5: 패리티를 분산해 병목을 줄이고, 쓰기 성능을 개선한다.
- RAID6: 패리티를 2개 관리해 안정성을 더욱 높인다.
4. 입출력(I/O) 기법
4.1 장치 컨트롤러와 장치 드라이버
- CPU가 모든 입출력 장치의 작동 방식을 직접 알기는 어렵다.
- 장치 컨트롤러(하드웨어)가 장치와 CPU 사이를 중개하고, 장치 드라이버(소프트웨어)가 장치 컨트롤러를 제어한다.
입출력을 수행하는 방법은 크게 3가지로 분류할 수 있다.
4.1.1 프로그램 입출력
- 명령어로 직접 입출력을 수행하는 방식이다.
- 고립형 I/O: 메모리 주소와 별개로 I/O 주소 공간을 따로 둔다.
- 메모리 맵 I/O: 메모리 주소 일부를 I/O 장치에 할당한다. 별도의 I/O 명령어 없이 메모리 접근 형태로 처리한다.
4.1.2 인터럽트 기반 입출력
- 입출력 장치가 작업을 끝낸 시점에 CPU에 인터럽트를 걸어 작업 완료를 알린다.
- 여러 장치에서 동시에 인터럽트가 발생하면, PIC(프로그래머블 인터럽트 컨트롤러)가 우선순위를 판단해 CPU에 알려준다.
4.1.3 DMA(Direct Memory Access) 입출력
- DMA 컨트롤러를 이용하면 CPU가 직접 데이터를 주고받지 않아도, 장치와 메모리 사이에서 고속의 데이터 전송이 가능하다.
- 버스는 한 번에 한 장치만 사용할 수 있으므로, DMA가 버스를 사용할 때 CPU는 잠시 버스를 이용하지 못한다. 이를 사이클 스틸링*이라 부른다.
5. GPU
- GPU(Graphic Processing Unit)는 원래 대량의 그래픽 연산을 빠르게 처리하기 위해 탄생했다.
- 최근에는 그래픽 연산뿐 아니라 데이터 연산, 딥러닝, 가상화폐 채굴 등 대규모 병렬 계산이 필요한 분야에서 활용된다.
- GPU는 코어(연산 유닛)가 수백~수천 개에 달해, 여러 연산을 동시에 처리하는 병렬 처리에 특화되어 있다.
- 반면 CPU는 복잡한 범용 연산을 수행하는 능력이 뛰어나며, 메모리 접근 최소화가 핵심 목표이다.
- 둘은 상호 보완적 역할을 하며, GPU를 보조프로세서(coprocessor)라 부르기도 한다.
5.1 CUDA 프로그래밍 모델
- NVIDIA가 개발한 CUDA는 GPU 프로그래밍을 쉽게 해주는 모델이다.
- CPU가 실행할 호스트 코드와 GPU가 실행할 디바이스 코드**로 구분된다.
- 예시 코드:
#include <stdio.h>
__global__ void cuda_hello(){
printf("Hello World from GPU!\n");
}
int main(){
cuda_hello<<<1,1>>>();
cudaDeviceSynchronize();
return 0;
}cuda_hello라는 디바이스 함수를 호출하면 GPU가 해당 함수를 실행하고,cudaDeviceSynchronize()로 CPU는 GPU 실행이 끝나길 기다린다.
마무리
- 메모리와 캐시 구조는 CPU 성능에 직접적인 영향을 주며,
- 보조 기억 장치 및 I/O 기법은 시스템 전체의 데이터 흐름을 결정하고,
- GPU(GPGPU)는 병렬 처리를 극대화하여 CPU가 처리하기 어려운 대규모 연산을 빠르게 해결합니다.
참고
_이것이 취업을 위한 컴퓨터 과학이다 with CS 기술 면접 – 한빛미디어_